Foundation Model vs LLM: Key Differences Explained

 CEO of Label Your Data
CEO of Label Your Data
Table of Contents
- TL;DR
- LLM vs. Foundation Model: What Sets Them Apart
- Modality Scope: How Foundation Models Go Beyond LLMs
- Pretraining Data Sources and Bias Risks
- Foundation Model vs LLM Training Paradigms
- Scaling Patterns and Capabilities in Practice
- Foundation Model vs LLM: Inference Costs and Deployment
- How Evaluation and Benchmarking Stack Up
- Choosing and Using Foundation Model vs LLM
- About Label Your Data
- FAQ

TL;DR
LLM vs. Foundation Model: What Sets Them Apart
There’s always confusion between foundation models and large language models. They sound similar, and they are, but there’s nuance that matters, especially when you’re building a product.
In this article, we’ll look at foundation models vs large language models to properly define the differences.
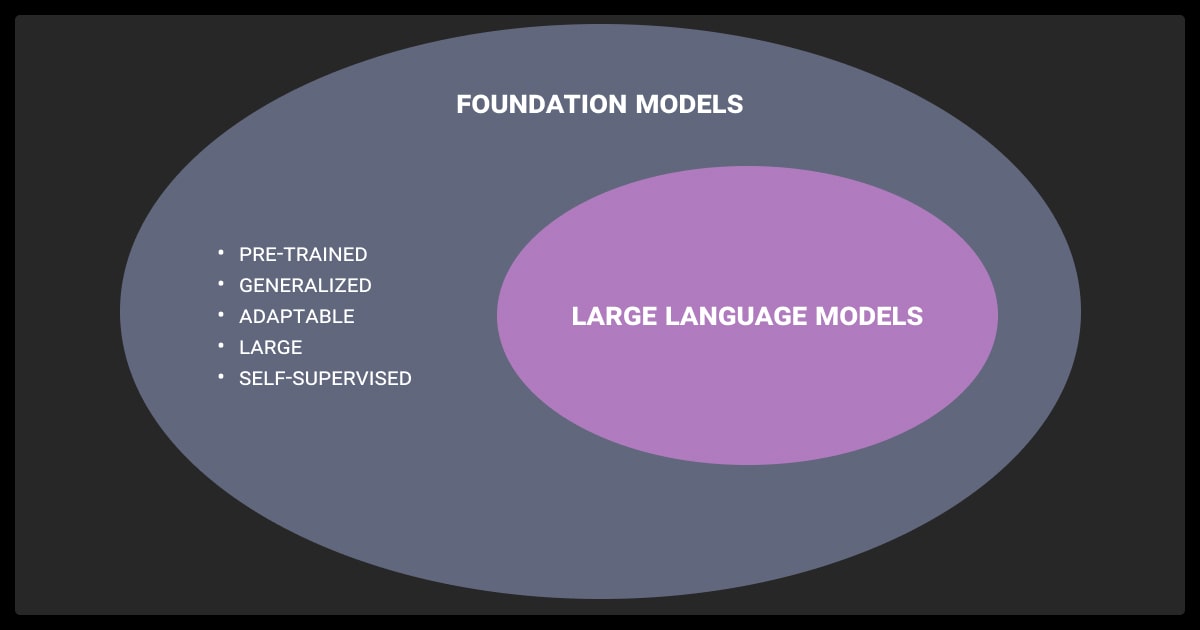
Foundation Models
A good foundation model vs. LLM example is to think of the trunk of a massive deciduous tree. You train it on diverse, gigantic machine learning datasets. It learns general-purpose representations, not for just one problem, but many.
What is a foundation model? It’s a model that isn’t tied to text. It sits in parameter space, able to learn patterns from pixels, text tokens, audio waveforms, even graphs. Case in point, GPT-4o is a multimodal LLM that functions as a foundation model, while CLIP and SAM are non-language-centric foundation models trained for vision and vision-language tasks.
Architecturally, most LLMs use a decoder-only transformer setup optimized for generative tasks, while models like CLIP or SAM often use encoder or encoder-decoder structures suited for representation learning and discrimination tasks.
LLMs
An LLM foundation model is more focused. Write code, draft an email, analyze text, you’re speaking their language, literally. GPT-4, LLaMA, Mistral are trained on terabytes of text. They predict the next tokens. They shine in dialogue, summarization, translation, code generation; anything with sentences.
In that sense, all the different types of LLMs are foundation models, but only for language. They don’t handle images without additional layers. Confusing them means misunderstanding their capabilities.
Modality Scope: How Foundation Models Go Beyond LLMs
Here’s where divergence becomes practical.
Input Types
An LLM digests text. You can integrate vision modules (e.g., encoders) with an LLM, but this typically involves architectural modifications or additional training, not just LLM fine tuning.
Foundation models embrace multiple input types, just like humans. Vision-language models incorporate image recognition and answer questions. Audio models understand speech. Some multi-sensor models even ingest tabular data.
In a system built for diagnostics, for example, the foundation model could process medical images and clinical notes together, something no pure LLM could manage smoothly without additional pipelines.
Output Diversity and Task-Specific Differences
LLMs produce text. Usually. You could fine-tune GPT to output JSON or markup, but it still returns tokens.
Foundation models are more varied. CLIP returns embeddings. SAM outputs segmentation masks. Some models even output gestures or control instructions for bots. The output format depends entirely on the training objective and modality mix, very different from generative text sequences.
Pretraining Data Sources and Bias Risks
Data defines the model’s worldview, and its flaws.
Where the Data Comes From (and Why It Matters)
When you know how LLM work, you’ll understand the difference more easily. A foundational LLM trains on massive text corpora, Common Crawl, GitHub, and books. Rich in syntax, semantics, context. But by focusing on text alone, they inherit textual biases like polarized phrasing, political slant, gender bias in language.
Foundation models take on more like image-caption pairs, videos with narration, tabular data from finance. The broader the data, the more general the features, but also the more noise and unexpected quirks. Techniques like contrastive learning or curriculum learning are often employed to handle data noise and modality misalignment.
You might, for example, combine social media text with urban video data. It could create a powerful, but surprisingly fragile in unstructured outdoor scenes.
Data Noise and Bias Risks
At scale, data cleaning is messy. You fight duplication across formats, text appears in captions, metadata, OCR layers. You define toxic content thresholds that balance domain relevance and safety.
Clean as you go? Ideal, but costly. Most teams sample and align their data pipelines, not filter end-to-end. That creates gaps. For production models, especially multimodal ones, that gap is often where biases creep in.
If you don’t have the capacity to do so, you can hire data collection services to help clean up the data. A data annotation company can usually help you get the information you need.
When your domain mistakes have catastrophic business impact and general models lack your proprietary knowledge patterns, fine-tuning becomes essential rather than optional.
 CEO & Founder Lifebit
CEO & Founder LifebitFoundation Model vs LLM Training Paradigms

It matters how a model learns, and it’s not all the same.
Pretraining Objectives
LLMs rely on token prediction. You feed it a prompt and it tries to guess what comes next. It’s simple, scalable, and flexible.
But multimodal foundation models need different signals. CLIP aligns images and text with contrastive learning. BERT-style models delete tokens and ask you to predict them. All this shapes how the model embeds data, whether it understands semantics, whether it generalizes across domains.
Fine-Tuning and Instruction Tuning
LLMs get instruction-tuned. You collect prompt-response pairs, then fine-tune them or use RLHF. They learn to be polite, helpful, and sometimes persuasive, if not manipulative. You can use LLM fine-tuning services to make your machine learning algorithm even more helpful.
Instruction tuning is a subtype of fine-tuning where the model is trained on prompt–response pairs to follow human-written instructions. It differs from general fine-tuning, which might optimize for task-specific objectives without an instruction format (e.g., classification, segmentation).
When tuning foundation models, your targets change. You need to use bounding boxes, segmentation masks, and embedded vectors. You tailor the model to object detection or classification.
Multimodal tuning is more complex, because it doesn’t use “Please summarize.” Instead, it’s more specific data annotation instructions like, “Draw a bounding box around the dog in the image.”
That difference changes how you build pipelines, and it’s critical for real-world deployment. For those companies who are short on time or experts, it might pay to hire data annotation services to help. You’d have to balance data annotation pricing and the budget, of course, but the time you save may make this a worthwhile exercise.
If the model cannot mirror the thinking patterns and language of real experts in the domain, no prompt or retrieval trick will bridge that gap. Fine-tuning becomes the only way to deliver genuine expertise and build user trust.
 Head of Product & Engineering Enhancv
Head of Product & Engineering EnhancvScaling Patterns and Capabilities in Practice
Scaling improves performance, up to a point. Generalization and few-shot learning typically get better with model size. Larger LLMs often exhibit emergent capabilities like in-context learning and more advanced reasoning. But recent studies suggest these effects may follow smooth scaling laws rather than appearing suddenly.
Still, bigger models don't eliminate core issues. LLM hallucination persists. Multimodal models remain brittle, especially with image-text misalignment. These problems are rooted in architecture and data diversity, not just parameter count.
In practice, scaling from models like GPT-3 to GPT-4 has shown gains in complex reasoning (e.g., math or logic), but factual accuracy remains imperfect. Similarly, larger vision-language models perform better in well-lit conditions, yet still struggle in low-light or noisy inputs. Scale attenuates failure modes, but rarely eliminates them.
Foundation Model vs LLM: Inference Costs and Deployment
“Trained” is half the work. “Deployed” is the other half.
Memory, Latency, Throughput Constraints
LLMs follow known patterns: token count, beam search, GPU or CPU performance. You pressure-test with concurrent API calls.
Multimodal foundation models add baggage, vision encoders, large input data, pre- / post-processing. Real-time video processing? You suddenly need multiple GPUs. Edge deployment becomes more expensive, more complex.
Hosted APIs vs On-Prem Deployments
Need privacy? On-prem might be mandatory, especially if GDPR applies. But you need infrastructure: inference servers, GPU clusters, monitoring, compliance logs.
APIs are convenient, but costs vary. Commercial ones like OpenAI can get expensive at scale, while open-source models hosted via services like Hugging Face or Replicate offer more flexibility.
To reduce inference costs and latency, many teams apply model compression techniques like quantization (e.g., 8-bit, 4-bit weights) or distillation, where a smaller student model learns from a larger teacher. These are common in both LLM and multimodal deployments.
The fine-tuned model... could suddenly detect anomalies that required seeing 90+ days of related transactions simultaneously, something impossible with retrieval-based approaches.
 CEO Kove
CEO KoveHow Evaluation and Benchmarking Stack Up
What gets measured gets built well.
LLM Benchmarks
LLMs are typically evaluated with:
MMLU for multi-domain factual knowledge
TruthfulQA to measure hallucination and truthfulness
MT-Bench or AlpacaEval for dialogue quality
These benchmarks focus on text-based reasoning and coherence; but don’t capture image, video, or cross-modal understanding.
Foundation Model Benchmarks
Multimodal and vision-language foundation models require different metrics:
VQAv2, OK-VQA, and Winoground test visual question answering and grounded language understanding
Zero-shot object detection benchmarks (e.g., LVIS, COCO) measure generalization
MMMU and similar suites combine multiple modalities (text, image, audio) across diverse tasks
Evaluation must match input/output types. Using MMLU to measure a vision-language model’s reasoning won't surface real performance gaps.
Choosing and Using Foundation Model vs LLM
So now you have budget, goals, and engineering constraints. Which one?
Text-Only vs Multimodal Workflows
If you’re only dealing with text, an LLM is the right tool. Source documents, dialogue systems, code assistance all handled natively.
But if you need images and text, OTT platform metadata, medical imaging, surveillance analysis, you need a multimodal foundation model. Trading compute for modality pays off.
Real-World Deployment Patterns
Hybrid systems are common in production. A vision foundation model might process images and pass outputs, like detected objects or features, into an LLM for explanation or decision-making.
In other setups, embedding models generate similarity signals, which the LLM uses as context to complete downstream tasks.
Hybrid agents are shockingly effective when tasks require reasoning across modalities. But they’re operationally complex, different inference servers, inconsistent latency.
Tradeoffs in Build vs Adapt vs Compose
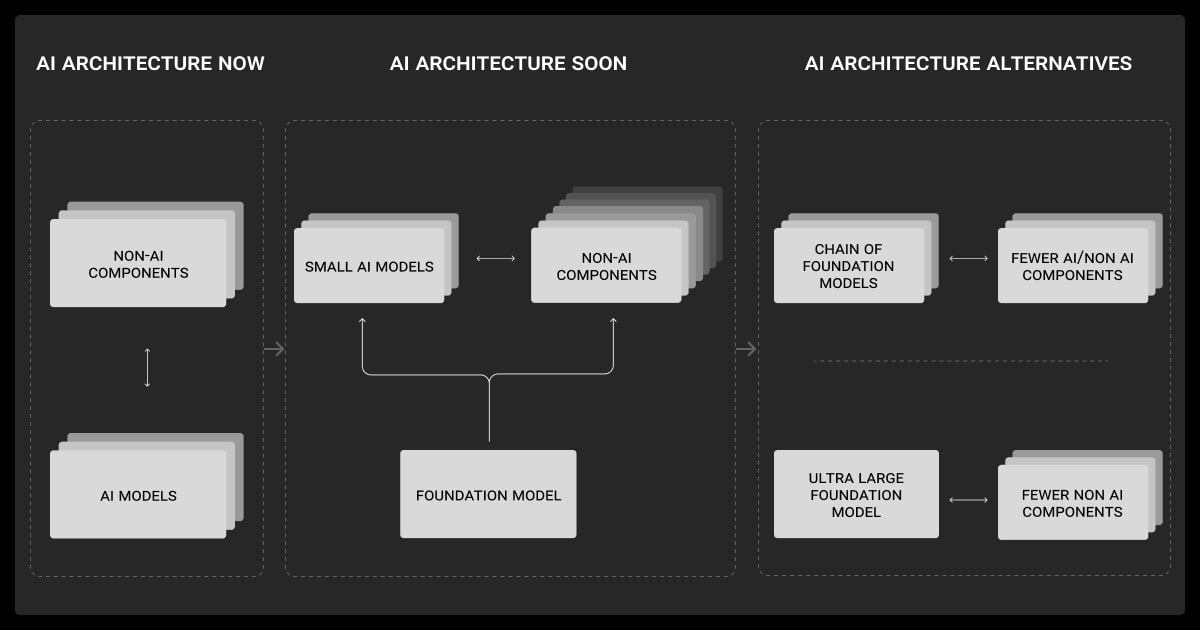
You can build a multimodal model from scratch, but that’s innovation-level effort. Most teams adapt or compose:
Adapt: Take existing foundation models, fine-tune with curated data or instruction-tune with labeled examples.
Compose: Chain specialized models via pipelines.
Build: Only if you have the compute and data to cover your specific tasks.
Adapt or compose often gets you 80% performance at 20% cost. Such ‘compose’ strategies are common in production agent systems, especially in retrieval-augmented setups using tools like LangChain or orchestration frameworks.
About Label Your Data
If you choose to delegate data annotation, run a free data pilot with Label Your Data. Our outsourcing strategy has helped many companies scale their ML projects. Here’s why:
No Commitment
Check our performance based on a free trial
Flexible Pricing
Pay per labeled object or per annotation hour
Tool-Agnostic
Working with every annotation tool, even your custom tools
Data Compliance
Work with a data-certified vendor: PCI DSS Level 1, ISO:2700, GDPR, CCPA
FAQ
What is the difference between a foundation model and an LLM?
A foundation model is a large pretrained network that can serve many tasks and modalities. An LLM is a foundation model that specializes in text. Every LLM is a foundation model, but not every foundation model is an LLM.
Does an LLM fall into the foundation model category?
Yes. LLMs are a subset, foundation models trained with language-only objectives and token prediction. They’re on the large-scale end of the same spectrum.
What is the difference between LLM and model?
“Model” is shorthand for any machine learning model. An LLM is a specific kind of model, a large, text-focused neural net. A foundation model is bigger in scope.
Is ChatGPT a foundation model?
Yes. ChatGPT is built on a foundation model (like GPT-4), which is a large pretrained transformer. It’s then fine-tuned with instructions and dialogue examples to behave conversationally.
Written by
CEO of Label Your Data
Karyna is the CEO of Label Your Data, a company specializing in data labeling solutions for machine learning projects. With a strong background in machine learning, she frequently collaborates with editors to share her expertise through articles, whitepapers, and presentations.